クラウドネイティブのCaaSプラットフォーム
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート
- スピーディーにデプロイ
- コスト削減
- 高可用性
- 優れたスケーラビリティ
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート




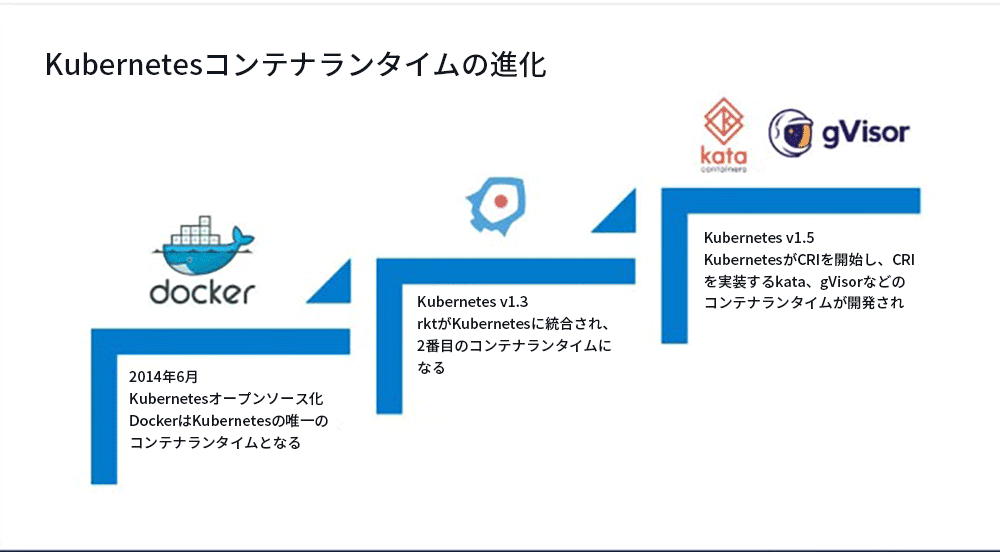
1. コンテナランタイムのプロセス進化
まず、コンテナランタイムの進化について理解しましょう。プロセス全体は、大きく3つの段階に分かれています。
2. RuntimeClassの一般的なワークフロー
上記の問題を解決するために、コミュニティはRuntimeClassを立ち上げました。これは実際にはKubernetes v1.12で導入されましたが、元々はCRDの形式で導入されました。 v1.14以降、組み込みクラスターリソースオブジェクトRuntimeClassとして導入されました。 v1.16は、v1.14に基づいてスケジューリングとオーバーヘッドの機能を拡張しました。
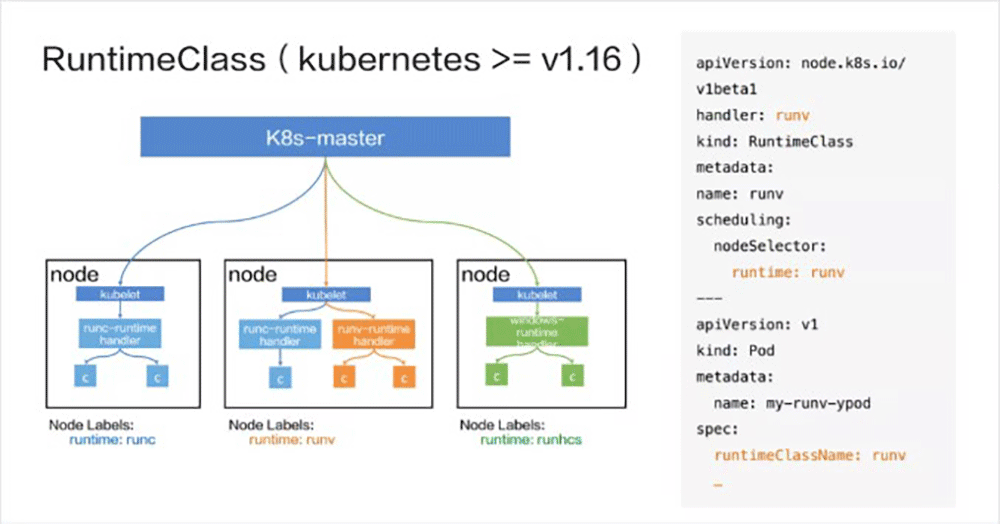
以下は、RuntimeClassのワークフローを説明するための例としてv1.16を取りあげます。 上の図に示すように、左側がワークフローのフローChart で、右側がYAMLファイルです。
YAMLファイルには2つの部分が含まれています。上部はrunvという名前のRuntimeClassオブジェクトの作成を担当し、下部はspec.runtimeClassNameを通じてRuntimeClass runvを参照するPodの作成を担当します。
RuntimeClassオブジェクトの中核はハンドラーです。これは、コンテナの作成要求を受信するプログラムを表し、コンテナランタイムにも対応します。 たとえば、上記例のPodは最終的にrunvコンテナランタイムによって作成されます。スケジューリングは、Podが最終的にスケジュールされるノードを決定します。
左側の図と合わせて、RuntimeClassのワークフローを説明します。
1. RuntimeClass 構造体の定義
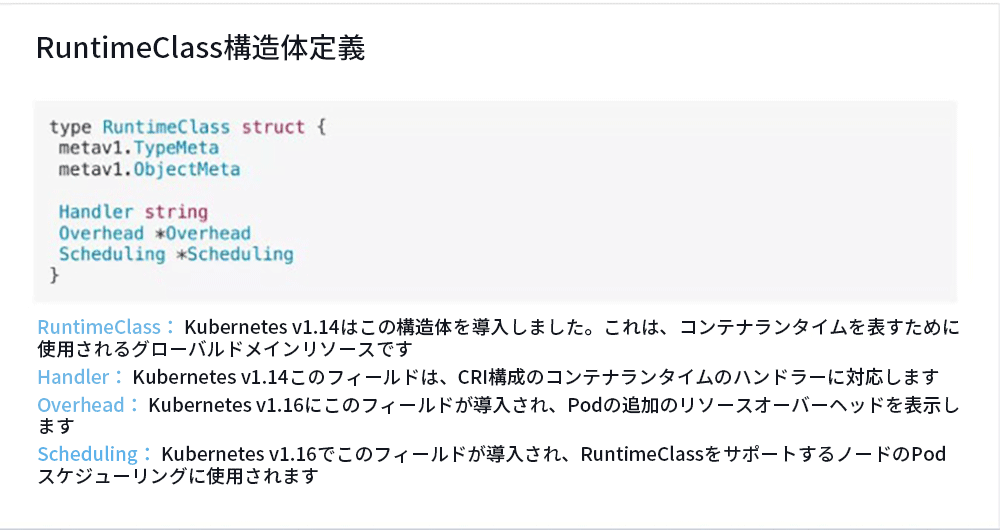
例として、Kubernetes v1.16のRuntimeClassを取り上げましょう。 まず、RuntimeClassの構造定義を紹介します。
RuntimeClassオブジェクトはコンテナランタイムを表し、その構造には主にHandler、Overhead、およびSchedulingの3つのフィールドが含まれます。
2. RuntimeClass リソース定義の例


PodでのRuntimeClassの参照の使い方は非常に簡単です。runtimeClassの名前がruntimeClassNameフィールドで構成されている限り、このRuntimeClassを導入できます。
3. Scheduling 構造体の定義
名前が示すように、Schedulingはスケジューリングを意味しますが、ここでのスケジューリングは、RuntimeClassオブジェクト自体のスケジューリングを意味するのではなく、RuntimeClassを参照するPodのスケジューリングに影響します。

スケジューリングには、NodeSelectorとTolerationsの2つのフィールドが含まれます。 これら2つは、Pod自体に含まれるNodeSelectorおよびTolerationsによく似ています。
NodeSelectorは、RuntimeClassをサポートするノード上にあるはずのラベルのリストを表します。 PodがRuntimeClassを参照した後、RuntimeClass admissionはラベルリストをPod内のラベルリストとマージします。 これらの2つのラベルの間に矛盾がある場合は、admissionによって拒否されます。 ここでの競合は、キーは同じであるが値が異なることを意味します。この場合、それらはadmissionによって拒否されます。
注意すべきもう1つの点は、RuntimeClassはNodeのラベルを自動的に設定しないため、ユーザーが使用する前に事前に設定する必要があることです。
Tolerationsは、RuntimeClassの許容範囲リストを表します。 PodがRuntimeClassを参照すると、admissionは許容リストをPod内の許容リストとマージします。 2つの許容差が同じ許容差設定を持つ場合、それらは1つにマージされます。
4. なぜPod Overheadが導入されたか?
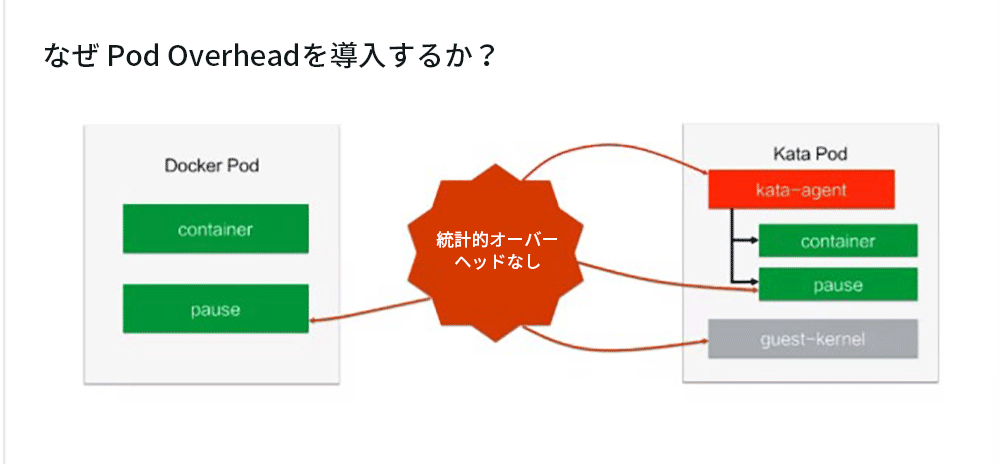
左側はDockerPod、右側はKataPodです。
従来のコンテナに加えて、Docker Podにはpauseコンテナもありますが、コンテナのオーバーヘッドを計算するときにpauseコンテナを無視します。 Kata Podの場合、コンテナ、kata-agent、pause、guest-kernelを除いてカウントされません。 これらのオーバーヘッドは、多くの場合100MBを超えることもあり、これらのオーバーヘッドは無視できません。
これが、Pod Overheadを導入するという当初の目的です。 その構造は次のように定義されています。
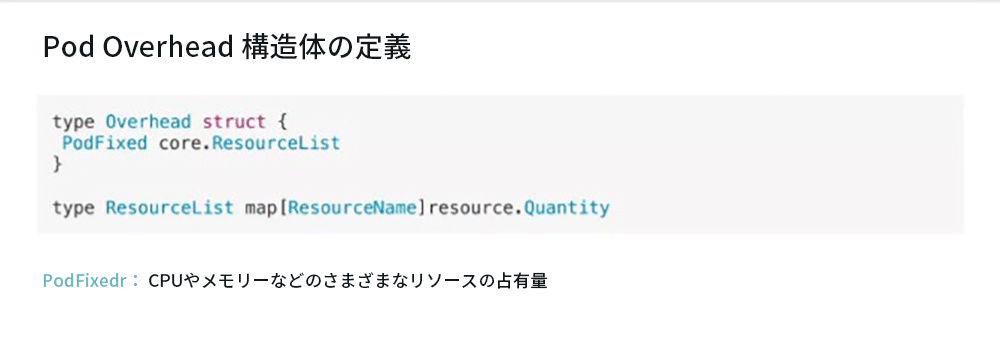
その定義は非常に単純で、PodFixedフィールドは1つだけです。 これは内部のマッピングでもあり、そのキーはResourceNameで、値はQuantityです。 各数量は、リソースの使用状況を表します。 したがって、PodFixedは、CPUやメモリーの占有率など、PodFixedを介して設定できるさまざまなリソースの占有率を表します。
5. Pod Overhead の使用シナリオと制限
Pod Overhead の使用シナリオは主に3つです。
HPAとVPAはコンテナレベルのメトリックデータに基づいて集計され、PodOverheadはそれらに影響しません。
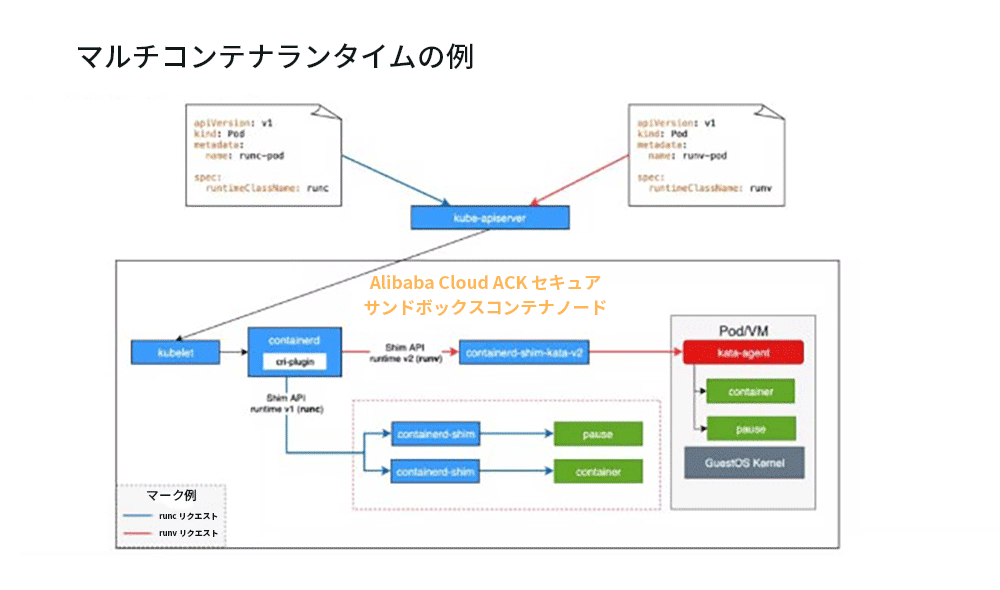
現在、Alibaba Cloud ACKセキュリティサンドボックスコンテナはマルチコンテナランタイムをサポートしています。上図に示す環境を例として、マルチコンテナランタイムの仕組みを説明します。
上の図に示すように、2つのPodがあります。左側はruncのPod、対応するRuntimeClassはrunc、右側はrunvのPod、および参照されるRuntimeClassはrunvです。
対応するリクエストは異なる色でマークされ、青はrunc、赤はrunvを表します。 図の下部では、コアパーツがcontainerdされています。containerdでは、複数のコンテナを実行するように構成できます。最後に、上記の要求もここに到着して要求を転送します。
まずruncのリクエストを見てみましょう。最初にkube-apiserverに到着し、kube-apiserverリクエストがkubeletに転送され、最後にkubeletがリクエストをcri-plugin(CRIを実装するプラグインです)に送信します。cri-pluginはcontainerdにあります 構成ファイルでruncに対応するハンドラーを照会し、最終的に、Shim APIランタイムv1を通じてcontainerd-shimが要求されていることを確認し、対応するコンテナを作成します。これがruncの流れです。
runvのフローはruncのフローに似ています。最初にkube-apiserverに到達し、次にkubeletに到達し、次にcri-pluginに到達します。cri-pluginは最終的に、containerdに一致する構成ファイルに戻り、最終的にShim APIランタイムv2によって作成されたcontainerd-shim-kata-createdを見つけます。 v2、それからKata Podを作成します。
次に、containerdの具体的な構成を見てみましょう。

containerdはデフォルトでfile:///etc/containerd/config.tomlに配置されます。 コア構成はplugins.cri.containerdディレクトリにあります。
ランタイムの構成には同じ接頭辞plugins.cri.containerd.runtimesがあり、その後に2つのRuntimeClass runc、runvが続きます。ここで、runcとrunvは、前のRuntimeClassオブジェクトのハンドラーの名前に対応しています。さらに、特殊な設定plugins.cri.containerd.runtimes.default_runtimeがあります。これは、PodがRuntimeClassを指定せず、現在のノードにスケジュールされている場合、デフォルトのruncコンテナを使用して実行することを意味します。
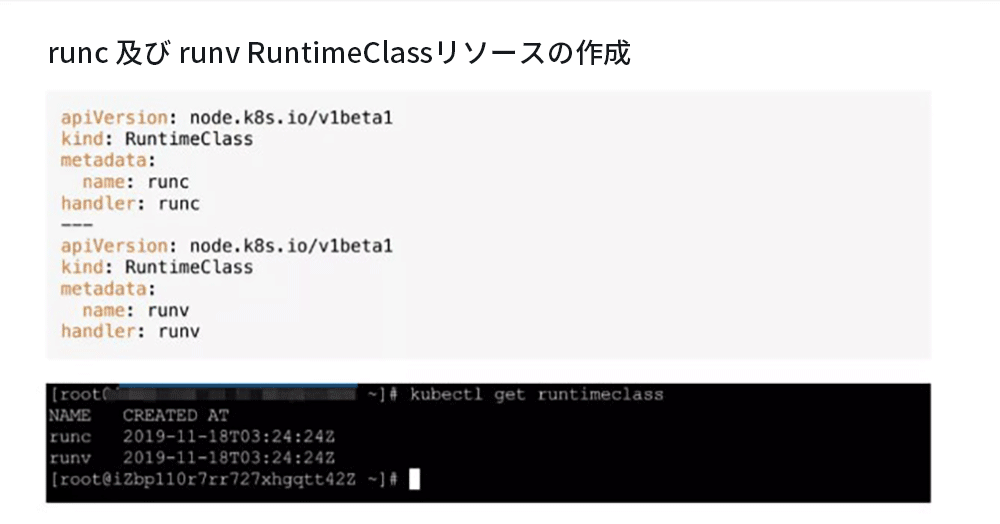
次の例では、runcとrunvの2つのRuntimeClassオブジェクトを作成しています。kubectlget runtimeclassを使用すると、現在使用可能なすべてのコンテナランタイムを確認できます。
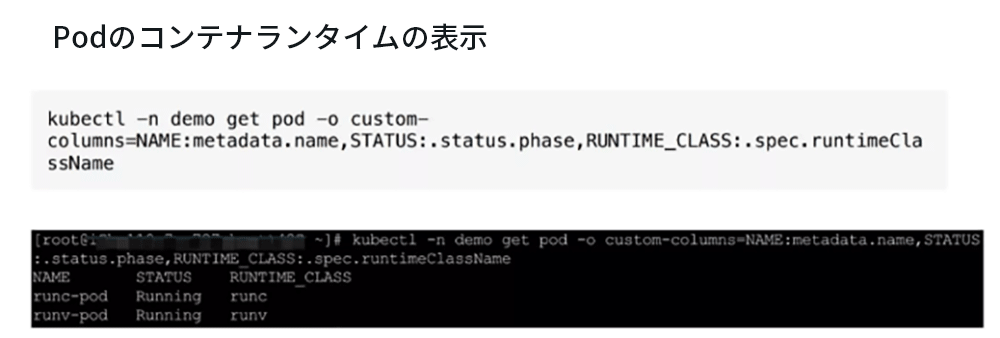
次の図は、runcとrunvのPodを左から右に示しています。比較の要点となるのは、runcとrunvのコンテナのランタイムがruntimeClassNameフィールドで参照されることです。

Podが最終的に作成された後、kubectlコマンドを使用して、各Podコンテナの実行ステータスと、Podで使用されるコンテナランタイムを表示できます。 クラスターに2つのPodがあることがわかります。1つはrunc-pod、もう1つはrunv-podで、それぞれruncとrunvのRuntimeClassを参照しており、それらの状態はどちらもRunningです。
この記事の主な内容はここまでです。ここに簡単にまとめます。