クラウドネイティブのCaaSプラットフォーム
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート
- スピーディーにデプロイ
- コスト削減
- 高可用性
- 優れたスケーラビリティ
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート




DailyMotionでは、3年前に業務環境でKubernetesの実装を開始しました。ただし、複数のクラスターにアプリケーションをデプロイすることは困難が伴うため、過去数年間、対応するツールとワークフローの作成に取り組んできました。
ここでは、世界中の複数のKubernetesクラスターにアプリケーションをデプロイする方法に焦点を当てます。
Kubernetesオブジェクトの複数のセットを一度にデプロイできるようにするために、Helmを使用して、すべてのChart を個別のGitリポジトリに保存します。 複数のアプリケーションスタックの完全なセットを展開できるようにするために、Umbrellaと呼ばれるChart を使用しました。これは依存関係の宣言をサポートし、コマンドラインを使用してAPI及び対応するサービスを開始できます。
さらに、Helmの上にpythonスクリプトを作成して、いくつかのチェック、Chart のビルド、キーの追加、アプリケーションのデプロイを行いました。これらのタスクはすべて、Dockerイメージを使用した集中型CIプラットフォームによって実現されました。
それでは本題に入っていきましょう。
注意:あなたがこのブログ投稿を読んでいる時点では、Helm 3は最初のRCバージョンをリリースしています。このバージョンは多くの便利な新機能をもたらし、これまでに検討してきた問題を解決します。
このアプリケーションでは、ブランチワークフローを使用して管理し、それをChart の開発にも適用することにしました。
各環境には、Chart を保存するための専用の保存域があります。 また、Chartmuseumを使用して、対応するAPIを公開しました。 このようにして、環境間の分離を強化し、これらのChart が本番環境で「集中」テストを受けていることを確認できます。
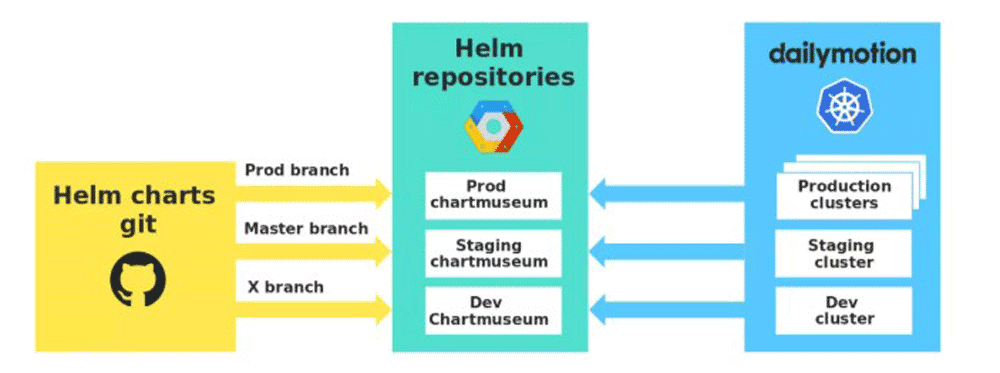
図:各環境のChart 保存域
開発者がdevブランチにプッシュすると、新しいバージョンのChart が自動的に開発環境のChartmuseumにプッシュされることに注意してください。この方法では、すべての開発者が同じ開発リポジトリを使用し、他の人のChart の変更を使用しないように、独自のChart バージョンを指定するように細心の注意を払う必要があります。
さらに、Pythonスクリプトはkubevalを使用してKubernetes OpenAPI定義を使用し、Chart をChartmuseumにプッシュする前に対応するKubernetesオブジェクトを確認します。
次の図は、Chart 開発ワークフローの概要です。
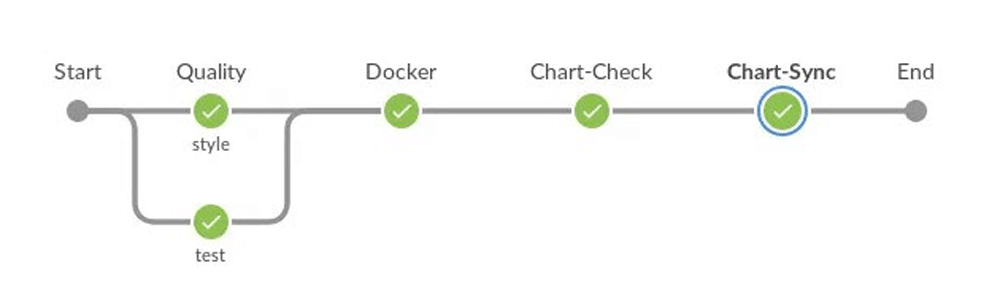
. gazr.ioによる品質タスク(lint、unit-test)の定義に従ってタスクフローを設定します。
2.アプリケーションのデプロイに使用されるpythonツールを含むDockerイメージをプッシュします。
3.ブランチ名に基づいて環境を設定します。
4. kubevalを使用してKubernetes yamlを確認します。
5.Chart のバージョンと対応する親子関係を自動的に増やします(変更されたChart によって異なります)。
6.環境に応じてChart をChartmuseumにプッシュします。
クラスター連携
場合によっては、Kubernetesクラスターフェデレーションを使用して、別のAPIでエンドポイントライフKubernetesオブジェクトにアクセスします。しかし、私達が直面している問題は、一部のオブジェクトをフェデレーションアクセスエンドポイントで作成できないため、フェデレーションオブジェクトや他の単一クラスターオブジェクトを維持することがより困難になることです。
この問題を緩和するために、クラスターを個別に管理して、プロセス全体を簡単に終了できるようにしました(v1クラスターフェデレーションを使用し、それに応じてv2が変更されます)。
地理的に分散したプラットフォーム
私達のプラットフォームは現在6つのリージョンにまたがっており、3つの自己構築および3つのクラウドデプロイメントが存在します。
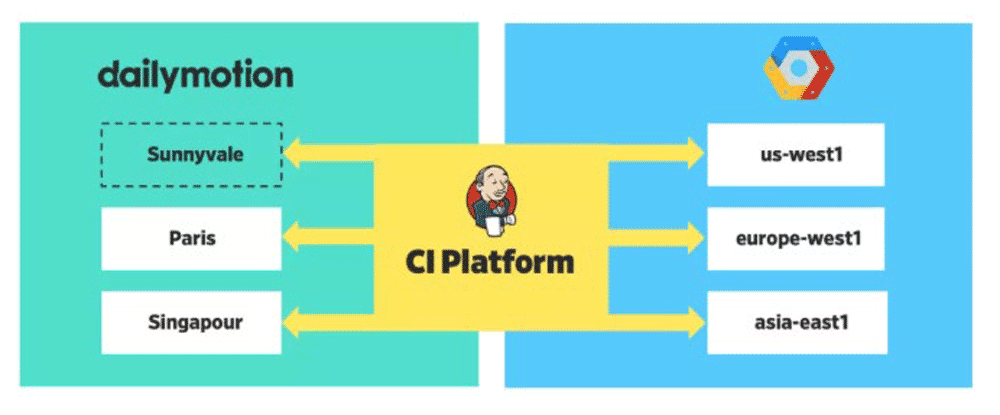
図:分散展開
4つのglobal Helm valueにより、異なるクラスター環境での対応する違いを定義できます。これらは、すべてのクラスターで最小化されるデフォルト値です。

Global value
この情報は、アプリケーションのコンテキストを定義するのに役立ちます。これらの情報は、監視、追跡、ログ記録、および外部呼び出しの生成、拡張などにも使用されます。
これは一例です:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}}
{{- define "graphql.hpaReplicas" -}}
{{- if eq .Values.global.env "prod" }}
{{- if eq .Values.global.region "europe-west1" }}
minReplicas: 40
{{- else }}
minReplicas: 150
{{- end }}
maxReplicas: 1400
{{- else }}
minReplicas: 4
maxReplicas: 20
{{- end }}
{{- end -}}
view rawhelm_template.yaml hosted with ❤ by GitHub
サービス定義
これは、導入ワークフローのすべてのステップを定義する概略図です。最後のステップは、複数の本番クラスターに同時にデプロイされます。
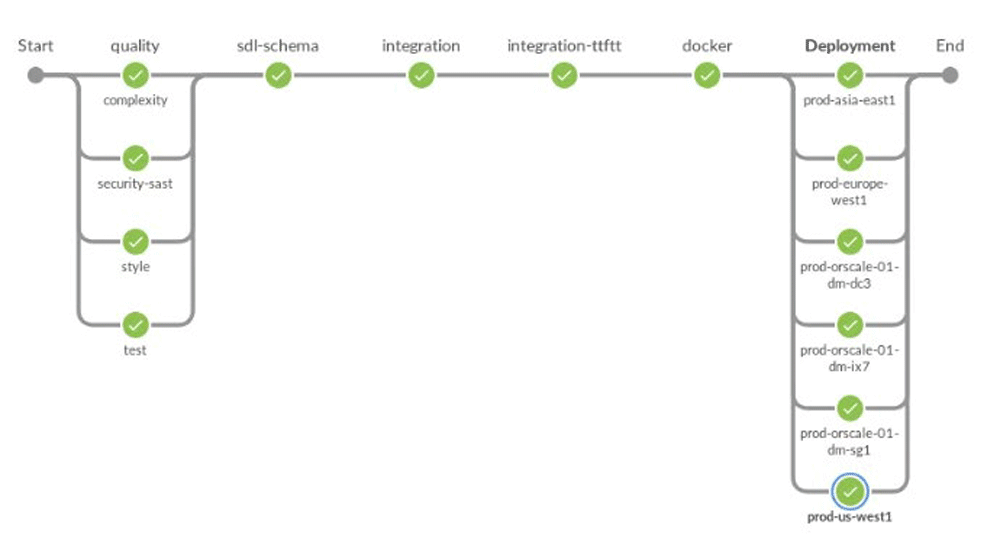
図:Jenkinsのデプロイ手順
セキュリティの分野では、さまざまな場所に分散している可能性のあるすべてのキーを追跡し、それらをパリの統一されたVaultバックグラウンドに保存することに重点を置いています。
私達の導入ツールは、Vaultからキーを取得し、実際の導入中にそれらをHelmに挿入する役割を果たします。
この効果を実現するために、Vaultキーとアプリケーション要件の間に保存されるマッピングを次のように定義しました。
secrets:
- secret_id: "stack1-app1-password"
contexts:
- name: "default"
vaultPath: "/kv/dev/stack1/app1/test"
vaultKey: "password"
- name: "cluster1"
vaultPath: "/kv/dev/stack1/app1/test"
vaultKey: "password"
view rawsecret_example.yaml hosted with ❤ by GitHub
apiVersion: v1
data:
{{- range $key,$value := .Values.secrets }}
{{ $key }}: {{ $value | b64enc | quote }}
{{ end }}
kind: Secret
metadata:
name: "{{ .Chart.Name }}"
labels:
chartVersion: "{{ .Chart.Version }}"
tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}"
type: Opaque
view rawsecret_template.yaml hosted with ❤ by GitHub
複数の倉庫を使用する
現在、アプリケーション開発プロセスはChart から切り離されています。つまり、開発者は2つのGitリポジトリで作業する必要があります。1つはアプリケーション用で、もう1つはKubernetesでのデプロイ方法を定義するためです。 実際、2つのGitリポジトリは2つのワークフローを意味し、これは新人を混乱させる可能性があります。
Umbrella Chart の管理は混乱を招く
Umbrella Chart について前述したように、これは依存関係を定義し、複数のアプリケーションを迅速に展開するのに役立ちます。ただし、オプション–resue-valuesを使用して、アプリケーションがデプロイされるたびにすべての値が渡されるのを回避する事もできます。これもUmbrella Chart の一部です。
継続的なリリースのワークフローでは、頻繁に変更される値は、コピー数とミラーtag(バージョン)の2つだけです。他のより安定した値の場合、それらを変更するには手動で更新する必要があり、判別が困難です。さらに、Umbrella Chart の小さなエラーがAlibaba Cloudに深刻な結果をもたらす可能性があります。私達は、それを目の当たりにしました。
複数の構成ファイルの更新
新しいアプリケーションを追加する場合、開発者は複数のファイルを変更する必要があります。アプリケーション宣言、キーリスト、アプリケーションがUmbrella Chart の一部である場合は、対応する依存関係に追加します。
Jenkinsの権限がVaultで拡張されている
現在、VaultのすべてのSecretを読み取ることができるAppRoleがあります。
ロールバックプロセスは自動化できません
ロールバックでは、複数のクラスターでコマンドを実行する必要があるため、エラーが発生しやすくなります。この操作とメンテナンス操作は、正しいバージョン番号を使用するために手動で実行します。
私達の目標
私達の考え方はデプロイするChart をアプリケーションリポジトリに配置することです。
このワークフローは開発と同じです。たとえば、ブランチがマスターにマージされるたびに、デプロイメントが自動的にトリガーされます。この方法と現在のワークフローの違いは、各部分がGit(アプリケーション自体と、Kubernetesにデプロイされる方法)によって管理されることです。
これには多くの利点があります。
2段階の移行
開発者はこれらのワークフローを2年以上使用してきたため、できるだけスムーズに移行を完了する必要があります。そのため、目標を達成する前に中間ステップを追加することにしました。
1段階目はとても簡単です。
apiVersion: "v1"
kind: "DailymotionRelease"
metadata:
name: "app1.ns1"
environment: "dev"
branch: "mybranch"
spec:
slack_channel: "#admin"
chart_name: "app1"
scaling:
- context: "dev-us-central1-0"
replicas:
- name: "hermes"
count: 2
- context: "dev-europe-west1-0"
replicas:
- name: "app1-deploy"
count: 2
secrets:
- secret_id: "app1"
contexts:
- name: "default"
vaultPath: "/kv/dev/ns1/app1/test"
vaultKey: "password"
- name: "dev-europe-west1-0"
vaultPath: "/kv/dev/ns1/app1/test"
vaultKey: "password"
view rawscalerelease.yaml hosted with ❤ by GitHub
私達はすべての開発者の間でこの用語を広めており、移行プロセスはすでに始まっています。最初のステップは引き続きCIプラットフォームによって制御されます。近々、別のブログにて2番目のステップについて説明します。Fitを使用してGitOpsワークフローに移行するにはどうすればよいか。セットアップと、直面する課題(複数の倉庫、鍵)について説明します。ぜひご期待ください。 近年のアプリケーション開発ワークフローがGitOpsに向けてどのように導いてきたかを説明しようとします。この旅はまだ終わりません。今後もブログ投稿を公開していきます。物事をできるだけシンプルに、開発者の習慣に近づけることが正しい選択であると信じています。